昨天介紹完kmeans演算法程式前半段,今天就要把後半段內容給寫完:
首先回顧一下昨天我們得到這個分類圖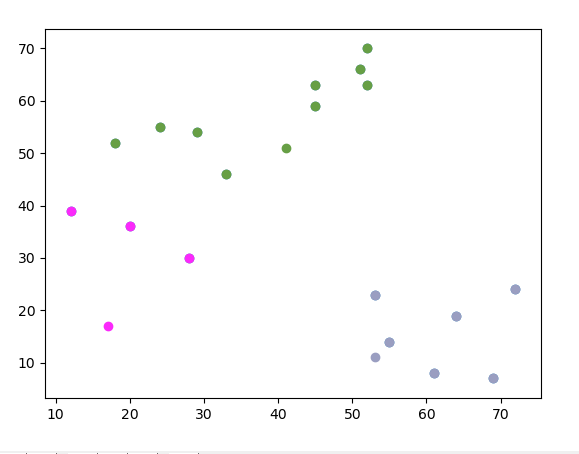
接下來就要算這個類個別的中心點:
程式如下:
#建立動態列表
for j in range(d):
locals()['data_'+str(j+1)] = []
#幫資料分類
for i in range(len(label_data_x)):
k=[]
for j in range(d):
#計算歐式距離
value_k=np.sqrt((x_y_used[j][0]-label_data_x[i])**2+(x_y_used[j][1]-label_data_y[i])**2)
k.append(value_k)
#取最小
tmp = min(k)
index = k.index(tmp)
#print("第",i+1,"筆資料為第",index+1,'類')
#分類資料添加到每一組
locals()['data_'+str(index+1)].append([label_data_x[i],label_data_y[i]])
#畫在圖上
plt.scatter(label_data_x[i],label_data_y[i],color=color_used[index])
plt.show()
#顯示每一組資料
for j in range(d):
print(locals()['data_'+str(j+1)])
結果如下:
[[45, 59], [52, 63], [18, 52], [52, 70], [45, 63], [24, 55], [33, 46], [29, 54], [51, 66]]
[[72, 24], [53, 23], [55, 14], [61, 8], [69, 7], [64, 19]]
[[20, 36], [12, 39], [28, 30]]
接下來對於這d筆資料來找出每組中心點(把顏色調淡),程式如下:
for j in range(d):
# print(locals()['data_'+str(j+1)])
#取平均點
label_x=[i[0] for i in locals()['data_'+str(j+1)]]
label_y=[i[1] for i in locals()['data_'+str(j+1)]]
xi=np.mean(label_x)
yi=np.mean(label_y)
print(xi,yi)
#劃出中心點並調淡
plt.scatter(xi,yi,color=color_used[j],alpha=0.5)
plt.show()
如圖: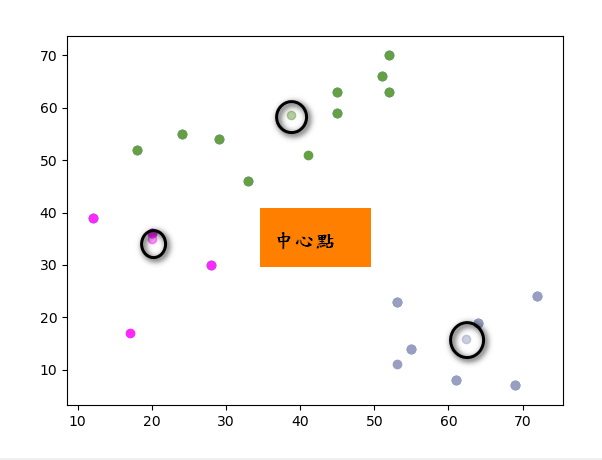
所以接下來就是迴圈直到所有類別不變動
所以程式如下:(在幫資料分類那段要加上old_label)
#幫資料分類
for i in range(len(label_data_x)):
k=[]
for j in range(d):
#計算歐式距離
value_k=np.sqrt((x_y_used[j][0]-label_data_x[i])**2+(x_y_used[j][1]-label_data_y[i])**2)
k.append(value_k)
#取最小
tmp = min(k)
index = k.index(tmp)
print("第",i+1,"筆資料為第",index+1,'類')
#添加所有index資料
old_label.append(index+1)
#分類資料添加到每一組
locals()['data_'+str(index+1)].append([label_data_x[i],label_data_y[i]])
#畫在圖上
plt.scatter(label_data_x[i],label_data_y[i],color=color_used[index])
plt.show()
之後新中心點要加上x_check和y_check程式碼如下:
#顯示每一組資料
x_check=[]
y_check=[]
for j in range(d):
# print(locals()['data_'+str(j+1)])
#取平均點
label_x=[i[0] for i in locals()['data_'+str(j+1)]]
label_y=[i[1] for i in locals()['data_'+str(j+1)]]
xi=np.mean(label_x)
yi=np.mean(label_y)
x_check.append(xi)
y_check.append(yi)
print(xi,yi)
#劃出中心點並調淡
plt.scatter(xi,yi,color=color_used[j],alpha=0.5)
接著幫新資料加上old_label2
old_label2=[]
#幫資料分類
for i in range(len(label_data_x)):
k=[]
for j in range(d):
#計算歐式距離
value_k=np.sqrt((x_check[j]-label_data_x[i])**2+(y_check[j]-label_data_y[i])**2)
k.append(value_k)
#取最小
tmp = min(k)
index = k.index(tmp)
print("第",i+1,"筆資料為第",index+1,'類')
#添加所有index資料
old_label2.append(index+1)
#分類資料添加到每一組
locals()['data_'+str(index+1)].append([label_data_x[i],label_data_y[i]])
#畫在圖上
plt.scatter(label_data_x[i],label_data_y[i],color=color_used[index])
plt.show()
print(old_label2)
print(old_label)
這樣就會產生新的圖和新的label
[1, 1, 3, 2, 3, 3, 2, 1, 1, 1, 1, 3, 1, 2, 2, 2, 2, 1]
[1, 1, 1, 2, 3, 3, 2, 1, 1, 1, 1, 3, 1, 2, 2, 2, 2, 1]
只要label不一樣,就重複這個動作直到label完全一樣
while部分就留給大家自己練習-->基本上就是如果不一樣就把old_label2傳給old_label(更新),並且while後面算中心點地方一直到求出old_label2
好,今天講解關於kmeans演算法結束,明天就要講解DBSCAN
在娃娃指引下,男孩走回了木屋,男孩看著焦黑的木屋,心理在猶豫要不要過去,在男孩這麼想同時,娃娃突然開始唱歌,就這樣男孩走到木屋門口,突然有二個身影從木屋裡衝了出來,朝男孩衝了過來,只是在靠近男孩時,娃娃突然抬手,瞬間被彈飛,被彈飛的狐狸不可置信看著娃娃,而男子只是生氣得怒眼瞪著娃娃,男孩很訝異,娃娃有這種能力,但男孩心理同時也升起了一絲不安
--|我不是你的玩具,我的感情是我自己的|-- MC.SM

